AML Compliance


Sanctions screening systems rely on large volumes of regulatory watchlist data published by governments and international bodies. However, these lists are rarely delivered in consistent formats. Each regulator structures data differently, uses different naming conventions, and includes varying levels of identifying information.
Sanctions list normalisation is the process of transforming this inconsistent data into a structured, standardised format that screening engines can interpret reliably. Without normalisation, screening systems would struggle to compare customer or transaction data accurately against watchlists, resulting in excessive false positives or missed matches.
In practice, normalisation sits at the very beginning of the screening pipeline. It prepares raw sanctions data so that screening algorithms, fuzzy matching engines, and investigation workflows can operate effectively. When done correctly, it significantly improves both detection accuracy and operational efficiency.
Why Sanctions List Normalisation Matters
Sanctions lists are published by multiple authorities, each using their own data model. A single sanctioned entity may appear in several lists with slightly different spellings, identifiers, or formatting. Without normalisation, these inconsistencies can cause screening engines to interpret records incorrectly.
Authoritative sources such as the European Union sanctions database (EU Sanctions Map) provide consolidated sanctions information across EU regulations, but institutions must still transform this data into formats compatible with their screening systems.
Normalisation ensures that data fields such as names, aliases, dates of birth, and identification numbers follow consistent structures. This allows screening engines to evaluate attributes reliably and reduces the risk of inconsistent alert generation.
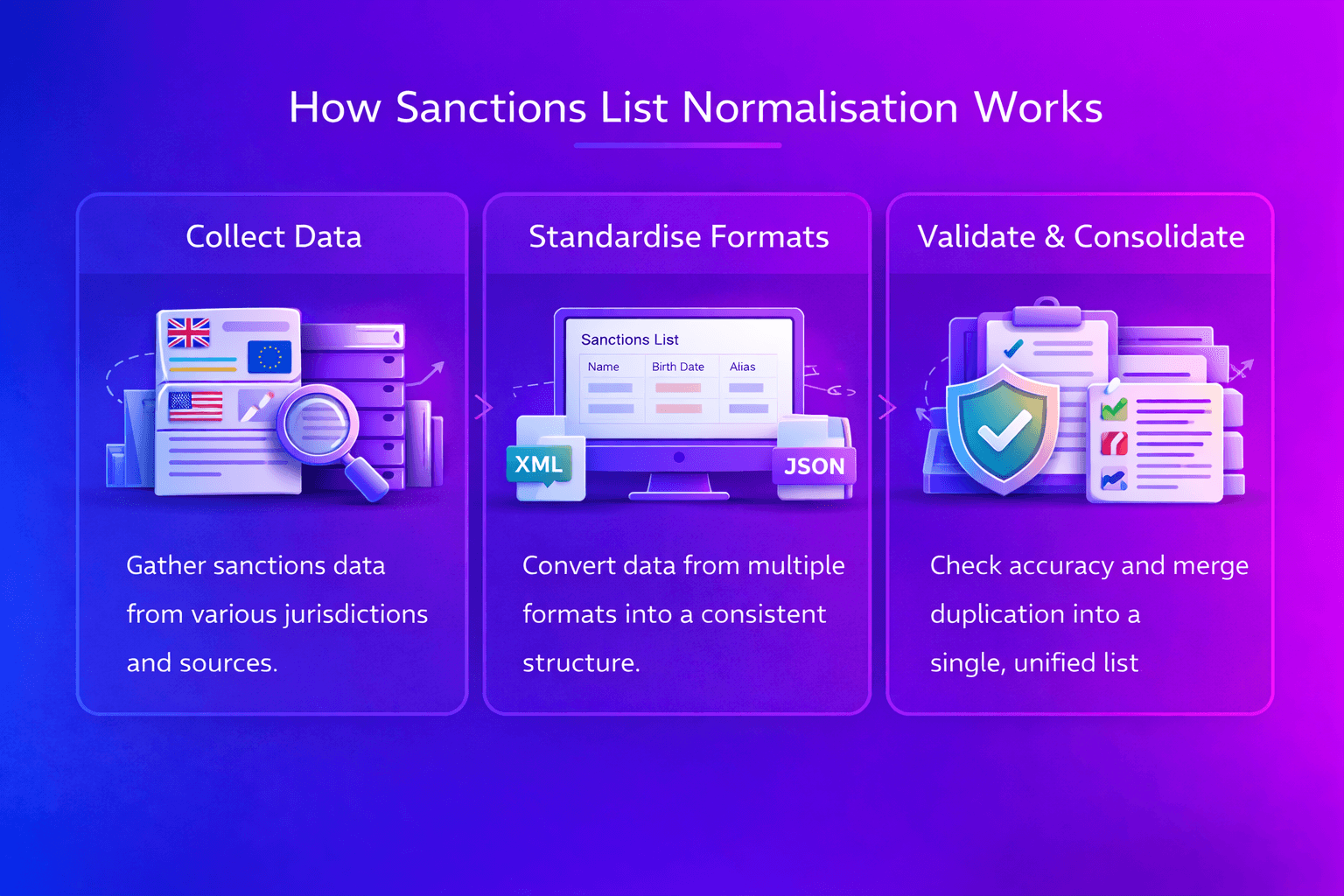
Where Normalisation Fits In The Screening Pipeline
Sanctions list normalisation occurs before any screening takes place. It prepares watchlist data so that screening engines can perform accurate comparisons.
Watchlist Data Collection
Regulatory lists are first collected from authoritative sources such as national sanctions authorities and international organisations.
Data Standardisation
During the normalisation process, list records are transformed into consistent field structures. Many organisations manage this stage through a structured watchlist management platform that ingests sanctions data from multiple sources and prepares it for screening.
Screening And Matching
Once normalised, screening engines evaluate customer or transaction attributes against the structured watchlist data. Systems such as modern customer screening solutions rely on this structured data to perform fuzzy matching and similarity analysis.
Alert Investigation
If potential matches are detected, alerts are generated and investigated using structured alert adjudication workflows that allow analysts to review identifying attributes and document investigation decisions.
Each of these stages depends on accurate and consistent watchlist data.
Key Steps In Sanctions List Normalisation
Normalisation typically involves several data processing stages.
Field Standardisation
Different sanctions lists may label similar information using different field names. Normalisation aligns these fields into a common schema so that screening engines interpret them consistently.
Name Parsing
Names are separated into structured components such as given names, surnames, and aliases. This improves fuzzy matching accuracy because algorithms can evaluate name components more effectively.
Alias Structuring
Sanctioned individuals often have multiple aliases or transliteration variations. Properly structuring alias fields allows screening engines to compare these variations more accurately.
Identifier Formatting
Dates of birth, passport numbers, national identification numbers, and other identifiers must follow consistent formatting rules so they can be evaluated reliably.
Duplicate Detection
Normalisation processes also identify duplicate records that appear across multiple sanctions lists. Deduplicating records prevents screening systems from generating multiple alerts for the same entity.
How Normalisation Improves Screening Accuracy
Well structured watchlist data significantly improves the performance of screening engines.
When data is normalised, screening systems can evaluate multiple attributes simultaneously rather than relying solely on name similarity. This allows the system to distinguish between genuine sanctions matches and unrelated individuals with similar names.
For example, combining name similarity with date of birth and nationality dramatically increases the accuracy of screening decisions.
As a result, normalised data helps reduce false positives while maintaining strong detection capability.
Common Watchlist Data Problems That Require Normalisation
Sanctions list data frequently contains issues that must be addressed before screening.
Inconsistent Name Formats
Different jurisdictions may publish names in varying formats or scripts.
Transliteration Variations
Names originally written in non Latin scripts may appear with multiple transliterations in sanctions lists.
Unstructured Alias Fields
Aliases may appear as free text rather than structured data.
Duplicate Records Across Lists
The same sanctioned individual may appear across several regulatory lists.
Normalisation resolves these issues so that screening engines operate on consistent and reliable data.
What Effective Watchlist Normalisation Looks Like
Organisations with mature screening programmes usually demonstrate several characteristics.
Automated Data Pipelines
Watchlist data is ingested and normalised automatically rather than manually.
Centralised Data Governance
A single system manages sanctions list ingestion, transformation, and distribution to screening engines.
Structured Data Models
Sanctions records follow consistent schemas that allow screening systems to compare attributes accurately.
Continuous Updates
List updates from regulators are applied quickly so screening engines always operate on the latest sanctions data.
These practices improve both detection reliability and operational efficiency.
Professional Insight And Operational Confidence
Sanctions list normalisation is often invisible to investigators reviewing alerts, yet it is one of the most important foundations of effective screening systems. When list data is inconsistent or poorly structured, even advanced screening algorithms struggle to produce reliable results.
Organisations that invest in strong data governance, automated ingestion pipelines, and structured watchlist schemas gain far greater confidence in the performance of their sanctions controls. Reliable data ensures that screening engines detect genuine risks while investigators focus their attention on meaningful alerts rather than operational noise.
Practical Experience
Compliance practitioners frequently find that improvements in data quality produce immediate improvements in screening performance.
Technical And Regulatory Expertise
Maintaining high quality watchlist data requires both technical data engineering capabilities and regulatory awareness.
Building Confidence In Controls
When sanctions data is well governed and consistently structured, organisations can demonstrate that their screening systems operate on reliable information.
People First Compliance Content
Financial crime compliance ultimately depends on the judgement of investigators and risk professionals who review alerts and interpret evidence. Technology assists this process by detecting potential matches, but the reliability of those alerts begins with the quality of the data used by screening systems.
Educational resources like this aim to support compliance professionals by explaining how technical processes such as list normalisation affect real world compliance operations.
Next Steps For Your Organisation
Many organisations discover during internal reviews that improvements in watchlist data governance significantly strengthen their sanctions screening framework.
If your organisation is evaluating its screening architecture or data governance processes, explore how your watchlist infrastructure compares with current industry practices.




